Multimodal Large Language Models (MLLMs) have made significant strides in natural images and satellite remote sensing images, allowing humans to hold a meaningful dialogue based on given visual content. However, understanding low-altitude drone scenarios remains a challenge, even for advanced MLLMs. Existing benchmarks primarily focus on a few specific low-altitude visual tasks, which cannot fully assess the ability of MLLMs in real-world low-altitude UAV applications. Therefore, we introduce UAVBench, a comprehensive benchmark, and UAVIT-1M, a large-scale instruction tuning dataset, designed to evaluate and improve MLLMs' abilities in low-altitude UAV visual and vision-language tasks. UAVBench comprises 43 test units and 966k high-quality data samples across 10 tasks at the image-level and region-level. UAVIT-1M consists of approximately 1.24 million diverse instructions, covering 789k multi-scene low-altitude UAV images and about 2,000 types of spatial resolutions with 11 distinct tasks, i.e, image/region classification, image/region captioning, VQA, object detection, visual grounding, etc. UAVBench and UAVIT-1M feature pure real-world visual images and rich weather conditions, and involve manual sampling verification to ensure high quality. Our in-depth analysis of 10 state-of-the-art MLLMs using UAVBench reveals that existing MLLMs cannot generate accurate conversations about low-altitude visual content. Extensive experiments demonstrate that fine-tuning MLLMs on UAVIT-1M significantly addresses this gap. Our contributions pave the way for bridging the gap between current MLLMs and low-altitude UAV real-world application demands.

Figure 1: UAVIT-1M supports 11 distinct tasks, spanning visual comprehension to vision-language reasoning, from image level to region level.
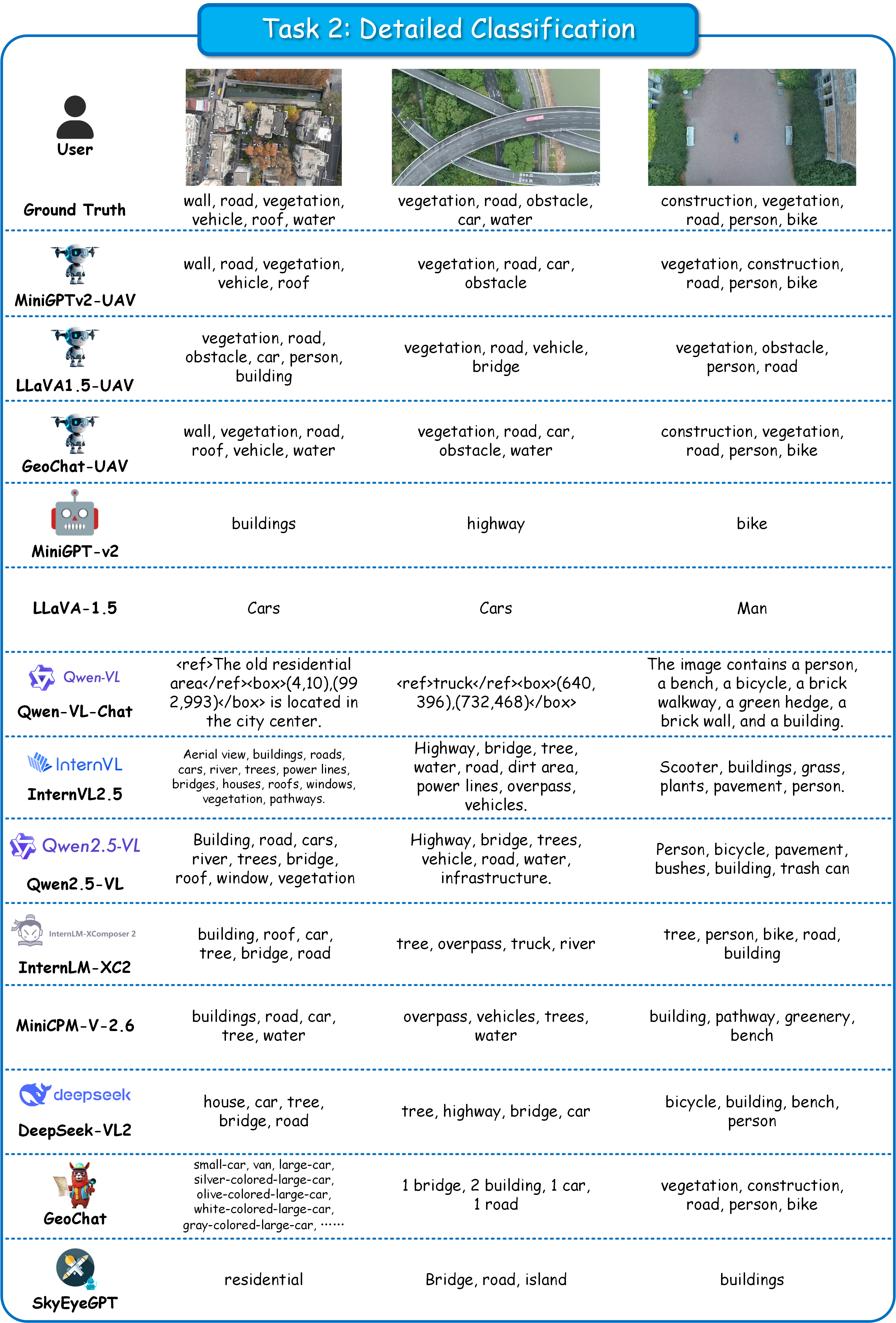
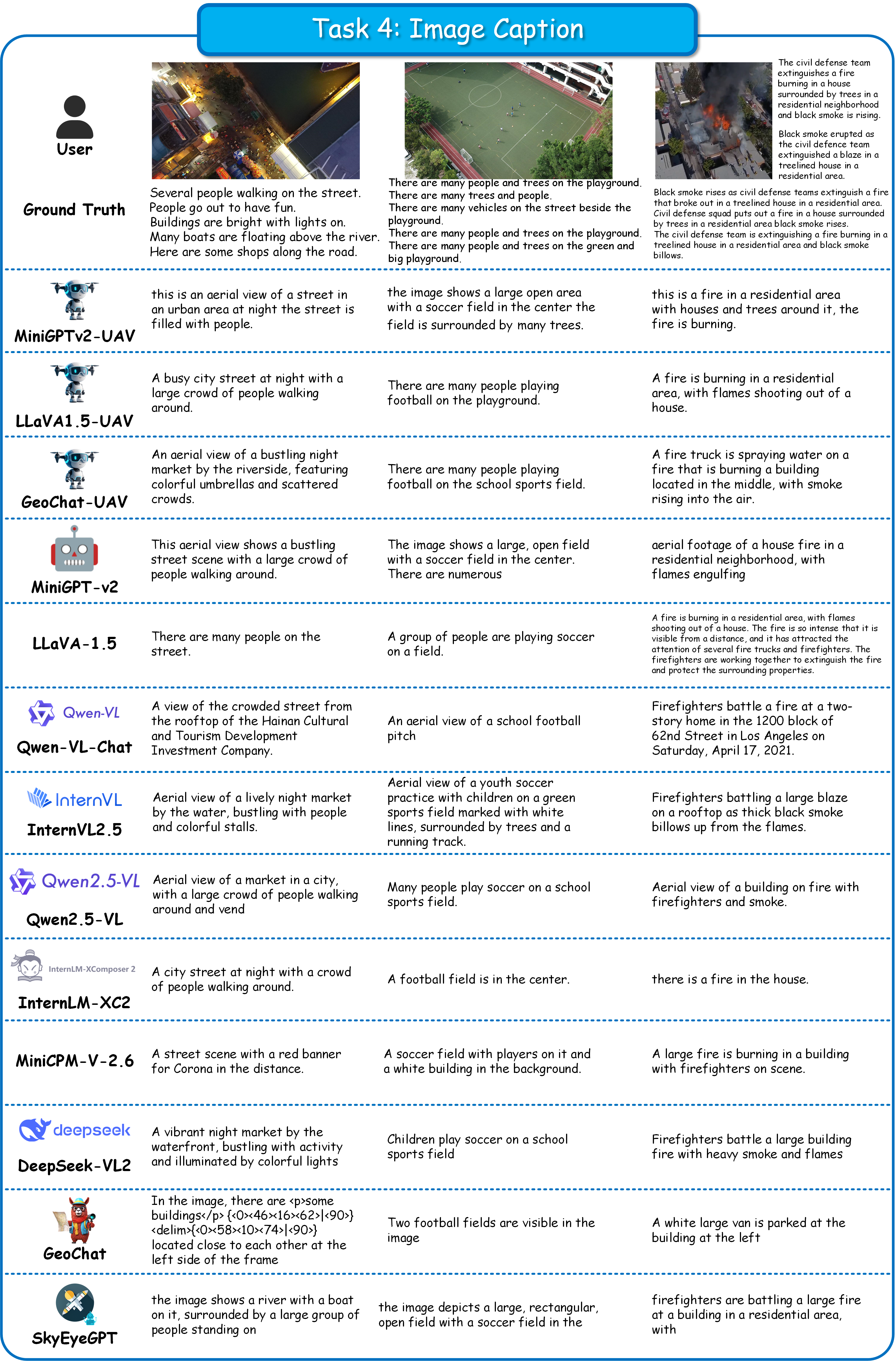
 UAVBench and UAVIT-1M
UAVBench and UAVIT-1M
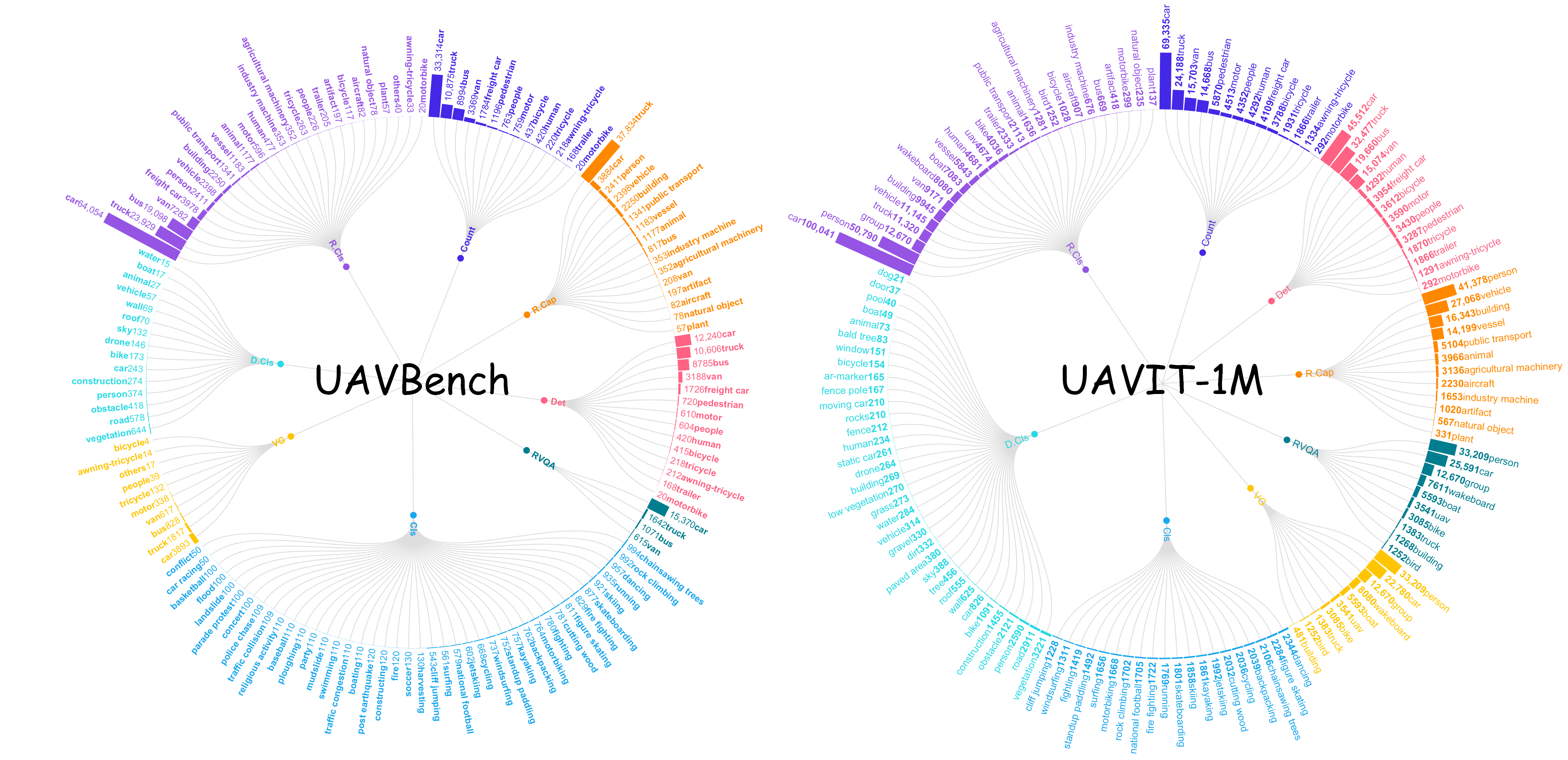
Figure 2: Category distribution in each task. Zoom in to view the specific categories and corresponding quantities.

Figure 3: Distribution of question types in image-level and region-level VQA tasks of UAVBench and UAVIT-1M.
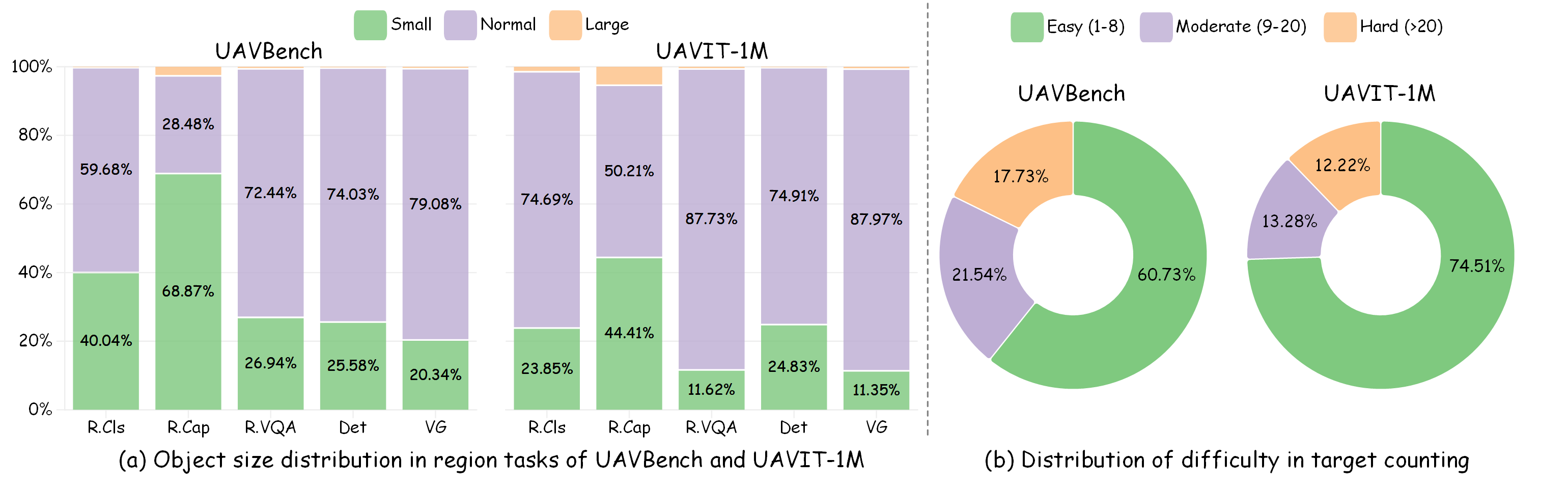
Figure 4: (a) Distribution of object sizes in all region-level tasks. (b) Distribution of difficulty in the target counting task.
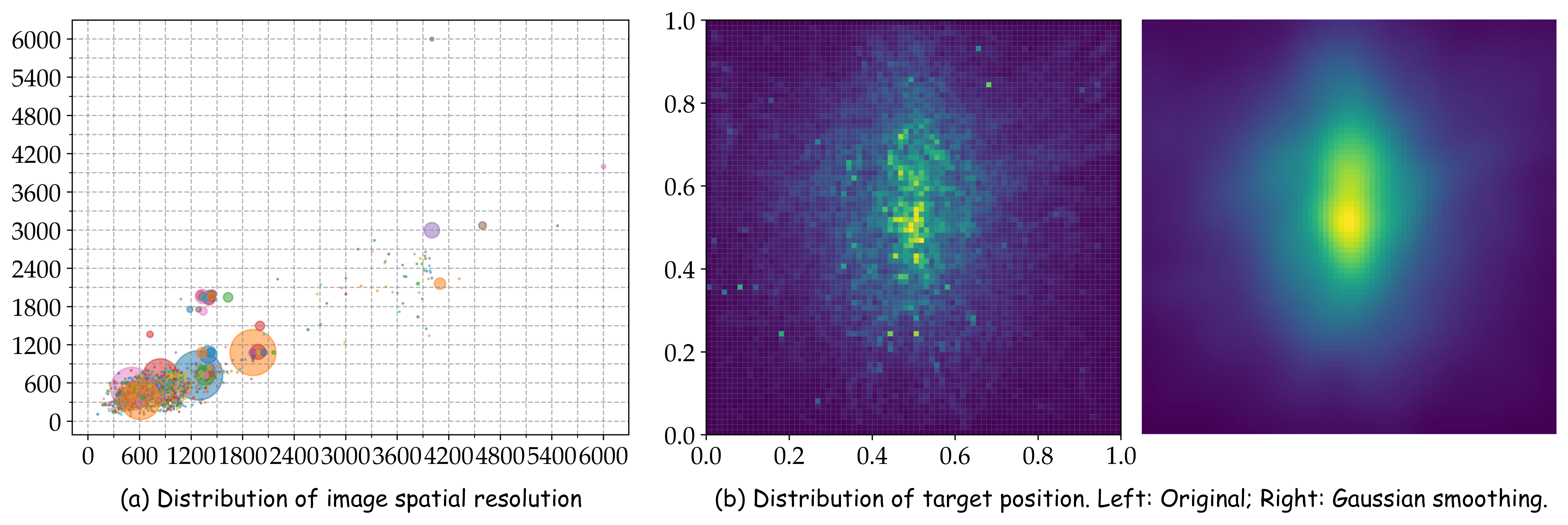
Figure 5: Image resolution and target position distributions in UAVIT1M. Best viewed by zooming in.


@article{2025uavbench,
title={{UAVBench and UAVIT-1M}: A Low-Altitude UAV Vision-Language Benchmark and Instruction-Tuning Dataset for MLLMs},
author={},
journal={},
year={2025}
}
This website is adapted from the Nerfies project page, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.